Advanced Spark Concepts for Job Interviews: Part 2
In this part, you’ll learn about spark memory allocation and memory management.
I recommend you to read Advanced Spark Concepts for Job Interview: Part 1 before getting started with this article.
SPARK Memory Allocation
Assume you submitted a spark application in a YARN cluster. The YARN RM will allocate an application master (AM) container and start the driver JVM in the container. The driver will start with some memory allocation which you requested.

You can ask for the driver’s memory using two configurations.
- spark.driver.memory
- spark.driver.memoryOverhead
So, let’s assume you asked for the spark.driver.memory as 1GB and the default value of spark.driver.memoryOverhead as 0.10
The YARN RM will allocate 1 GB memory for the driver JVM, and 10% of requested memory or 384 MB, whatever is higher for container overhead.
The overhead memory is used by the container process or any other non JVM process within the container. Your Spark driver uses all the JVM heap but nothing from the overhead.
So, the driver will again request the executor containers from the YARN. The YARN RM will allocate a bunch of executor containers.
The total memory allocated to the executor container is the sum of the following:
- Overhead Memory
- Heap Memory
- Off Heap Memory
- PySpark Memory
So, a Spark driver will ask for executor container memory using four configurations.
What are the configurations used for executor container memory?
- Overhead memory is the spark.executor.memoryOverhead
- JVM Heap is the spark.executor.memory.
- Off Heap memory comes from spark.memory.offHeap.size.
- The PySpark memory comes from the spark.executor.pyspark.memory.
So, the driver will look at all these configurations to calculate your memory requirement and sum it up.
The container should run on a worker node in the YARN cluster. What if the worker node is a 6 GB machine? YARN cannot allocate an 8 GB container on a 6 GB machine due to lack of physical memory. Before you ask for the driver or executor memory, check with your cluster admin for the maximum allowed value.
While using YARN RM, you should look for the following configurations.
- yarn.scheduler.maximum-allocation-mb
- yarn.nodemanager.resource.memory-mb
You do not need to worry about PySpark memory if you write your Spark application in Java or Scala. But if you are using PySpark, this question becomes critical.
PySpark is not a JVM process but overhead memory. Some of which is constantly consumed by the container and other internal processes. If your PySpark occupies more than accommodated in the overhead, you will see an OOM error.
Let’s have a quick recap
- You have a container, and the container has got some memory.
2. This total memory is broken into two parts: Heap memory( driver/executor memory) and Overhead memory (OS Memory)
3. The heap memory goes to your JVM.
4. We call it driver memory when running a driver in this container. Similarly, we call it executor memory when the container runs an executor.
The overhead memory uses for a bunch of things. The overhead uses for network buffers. So, you will be using overhead memory as your shuffle exchange or reading partition data from remote storage, etc.
Both the memory portions are critical for your Spark application. And more often, lack of enough overhead memory will cost you an OOM exception. As the overhead memory is overlooked, it is used as shuffle exchange or network read buffer.
Spark Memory Management
Let’s focus on the JVM memory in this part. The heap memory is further broken down into three parts.
- Reserved Memory
- Spark Memory Pool
- User Memory
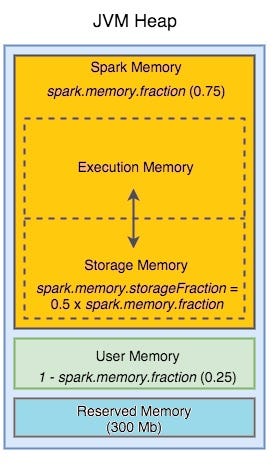
So, let’s assume I got 8 GB for the JVM heap. This 8 GB is divided into three parts. Spark will reserve 300 MB for itself. That’s fixed, and the Spark engine itself uses it.
The next part is the Spark executor memory pool, controlled by the spark.memory.fraction configuration, and the default value is 60%. So, for example, the spark memory pool translates to 4620 MB.
How do Spark Memory Pools work?
We have got 8 GB or 8000 MB. Three hundred is gone for Reserved memory. Right? We are remained with 7700 MB. Now take 60% of this, and you will get 4620 MB for the Spark memory pool. What is left? We are left with 3080 MB, and gone for user memory.
Now let’s try to understand the three memory pools.
- The Reserved Pool is gone for the Spark engine itself. You cannot use it.
2. The Spark Memory Pool is your main executor memory pool which you will use for data frame operations and caching.
The Spark memory pool is where all your data frames and data frame operations live. You can increase it from 60% to 70% or even more if you are not using UDFs, custom data structures, and RDD operations. But you cannot make it zero or reduce it too much because you will need it for metadata and other internal things.
Spark Executor Memory Pool is further broken down into two sub pools.
- Storage Memory
- Executor Memory
The default break up for each sub pool is 50% each, but you can change it using the spark.memory.storageFraction configuration.
We use the Storage Pool for caching data frames and the Executor Pool is to perform data frame computations.
3. The User Memory Pool is used for non data frame operations.
Here are some examples for User Memory Pool:
- If you created user defined data structures such as hash maps, Spark would use the User Memory Pool.
- Similarly, Spark internal metadata and user-defined functions are stored in the user memory.
- All the RDD information and the RDD operations are performed in user memory.
But if you are using Data Frame operations, they do not use the user memory even if the data frame is internally translated and compiled into RDD. You will be using user memory only if you apply RDD operations directly in your code.
END OF PART 2
